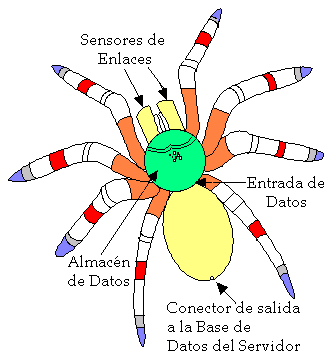
Un Web crawler indexador web, indizador web o araña web es un programa informático que navega he inspecciona las páginas del World Wide Web (www) por Internet de una manera predeterminada, configurable y automática, realizando acciones programadas en el contenido crawler. Los motores de búsqueda como Google y Yahoo utilizan rastreadores como medio de proporcionar datos de búsqueda, es decir, estos rastreadores encuentran y almacenan lo que luego tu vas a buscar.
Uno de los usos más frecuentes que se les da consiste en crear una copia de todas las páginas web visitadas para su procesado posterior por un motor de búsqueda que indexa las páginas proporcionando un sistema de búsquedas rápido. Las arañas web suelen ser bots.
¿Qué es Robots.txt y para qué sirve? Parte I
¿Cómo crear un archivo Robots.txt para un sitio web? Parte II
Política de Arrastre o Rastreo
El comportamiento de un buscador web es el resultado de una combinación de políticas:

Política de selección que establece las páginas de descarga,
Política de re-visita que establece cuándo debe buscar cambios en las páginas,
Política de cortesía que indica cómo evitar la sobrecarga de los sitios Web , y
Política de paralelización que indica la forma de coordinar los rastreadores web distribuidos
El robot de Google, al igual que el resto de los robots de buscador acreditados, respetará las directivas del archivo robots.txt, pero es posible que algunos spammers y otros usuarios malintencionados no las respeten.
Información de las crawlear:
vínculos de salida, grado de salida
texto
url
fecha de la última visita
El motor genera peticiones y gestiona eventos contra una acción.
Planificador : El planificador recibe las solicitudes enviadas por el motor y las pone en cola.
Descargador : El objetivo del descargador es buscar todas las páginas web y enviarlas al motor, el motor luego envía las páginas web a las arañas.
Arañas : Las arañas es el código que escribes para analizar sitios web y extraer datos.
Tubería de elementos:procesa los elementos lado a lado después de que las arañas los extraen.
DNS
DNS son las iniciales de Domain Name System (sistema de nombres de dominio) y es una tecnología basada en una base de datos que sirve para resolver nombres en las redes, es decir, para conocer la dirección IP de la máquina donde está alojado el dominio al que queremos acceder.
ROBOTS
Los motores de búsqueda visitan cada cierto tiempo los sitios web y rastrean el contenido de éstos a través de robots, también conocidos como arañas
NSLOOKUP
La herramienta NsLookup le permite proporcionar un nombre de host y solicitar uno o más tipos de registros DNS (por ejemplo, registros A, NS, CNAME).
PING
Para determinar si un servidor responde a las solicitudes. Usted proporciona una dirección IP o un nombre de dominio, y puede ver si el host responde o no.
WHOIS
Si tiene curiosidad sobre quién es la parte responsable (o las partes) detrás de un nombre de dominio, la consulta de WHOIS le permitirá consultar las bases de datos de múltiples registradores de dominio. Si el propietario ha optado por ocultar su información, puede devolver la información de reenvío.
Proyecto Loxosceles

Archivo bat
------------------------------------------------
::/bin/bat
::Requisito tener instalado wget en windows
::http://gnuwin32.sourceforge.net/
@echo off
echo.[+] Ingresa la url
set /p URL=:
echo. %URL%
wget %URL%/robots.txt>NUL
type robots.txt
pauseArchivo bash
------------------------------------------------
#!/bin/bash
#Requisito tener instalado wget en linux
#sudo apt-get install wget
echo [+] Ingresa la url:
read URL
echo $URL
echo $(date) Running wget...
wget "${URL}/robots.txt"
CAT robots.txt
read -rsp $Presione una tecla para continuar .\n

Podemos observar que hay paginas webs de WordPress que tienen el archivos robots,txt por defecto y otros archivos mas .

¿Por qué Feedfetcher no sigue las directivas de los archivo robots.txt?
Con Feedfetcher, Google obtiene los feeds RSS o Atom de Google Play Kiosco y PubSubHubbub. Feedfetcher recopila y actualiza periódicamente estos feeds iniciados por los usuarios, pero no los indexa en la Búsqueda de blogs ni en los otros servicios de búsqueda de Google (los feeds solo se muestran en nuestros resultados de búsqueda si han sido rastreados por el robot de Google)
[]Feedfetcher solo recupera los feeds cuando el usuario ha iniciado explícitamente un servicio o una aplicación que solicita datos de dichos feeds. Feedfetcher se comporta como un agente directo del usuario y no como un robot, por lo que ignora las entradas del archivo robots.txt.
Si quieres impedir que Feedfetcher rastree tu sitio web, configura tu servidor para que muestre mensajes de estado de error 404 o 410 o de cualquier otro tipo al user-agent Feedfetcher-Google.
Proyecto Loxosceles terminado

En el próximo blog publicare el programa completo pero he aquí les dejo cursos para puedan descargarlo y verlos sin publicidad disfrutenlo :)
Curso de Crawler
¿Qué es Robots.txt y para qué sirve? Parte I
¿Cómo crear un archivo Robots.txt para un sitio web? Parte II
https://www.matem.unam.mx/~rajsbaum/cursos/web/crawlers.pdf
Libro crawlers.pdf
https://mega.nz/F%3C/a%3E!pg0V0Y4A!DS1Kqc6S0xvtZ8qIqc4Ryw
Curso de pententesting
Referencias
⇜⇝⇜⇝⇜⇝⇜⇝
https://es.wikipedia.org/wiki/Ara%C3%B1a_web
https://github.com/msnoigrs/python-robotstxt
https://www.robotstxt.org/db.html
https://support.google.com/webmasters/answer/182072
https://support.google.com/webmasters/answer/178852
https://support.google.com/webmasters/answer/80553
https://support.google.com/webmasters/answer/1061943
https://support.google.com/websearch/answer/9109
https://support.google.com/webmasters/answer/48620?hl=es&ref_topic=9427949
https://support.google.com/webmasters/answer/35308?hl=es&ref_topic=4598466
http://api.hackertarget.com/subnetcalc/

------------------------------------------------
Únete a la comunidad Cyber Hacking
Conviértete en el mayor hacker del mundo Descarga gratis la app The Seven Codes y comparte
Google play Sígueme
ADVERTENCIA: NO INTENTE HACER UN ATAQUE SIN EL PERMISO DE PROPIETARIO DEL SITIO WEB. ES UN PROPÓSITO EDUCATIVO SOLAMENTE. NO ES RESPONSABLE DE NINGÚN TIPO DE PROBLEMA ILEGAL.
PERMANECE LEGAL. GRACIAS!
Si tienes algún problema, deja un comentario y comparte tú opinión.
¿Ha quedado contestada su pregunta?
atras
Mi nombre es Luishiño aquí es donde me gusta escribir sobre temas que en su momento me interesan. Aveces sobre mi vida personal y principalmente cosas de programación ,desarrollo web.Aplicaciones,Software, programas que yo mismo las desarrollo y cosas básicas de informática.
Fuente: este post proviene de The Seven Codes, donde puedes consultar el contenido original.
¿Vulnera este post tus derechos? Pincha aquí.
Creado: