Aquí es cuando también se añaden los términos de araña, Crawler o rastreadores, ya que el Bot se desplaza por los enlaces para abarcar todos los rincones de la web.
En el caso del navegador más utilizado del mundo (Google), su crawler es conocido como GoogleBot, un pequeño software que tiene la finalidad de categorizar todas las páginas existentes en Internet para asignarles un puesto en las SERPS en Google.
Aunque no lo creas, los recursos del buscador son limitados, por ese motivo, se asigna un presupuesto de rastreo o crawl budget en inglés que, básicamente, es un tiempo que se le asigna a cada sitio web para ser rastreado.
Si por una mala optimización On Page el Crawler no es capaz de alcanzar todas las URLs de un site, muchas no quedarán indexadas y posiblemente tu web no esté alcanzando todo su potencial
Es por eso que el crawling, se ha convertido en uno de los factores más importantes del SEO en los últimos años.
Ya que bien trabajado en una estrategia de posicionamiento web, puedes lograr excelentes resultados en cuanto al ranking y tráfico orgánico.
La importancia del Crawling
Como mencioné anteriormente, el crawling en un método que emplean los motores de búsqueda para conseguir examinar e indexar el contenido de un sitio web de acuerdo a su temática en los índices de cada navegador.Asimismo, los Bots se encargan de revisar el sitio en busca de contenido nuevo o actualizado para determinar el puesto por el cual pueden optar en sus resultados.
La realidad es que nadie sabe los estándares por los que se basa Google Bot para priorizar una web frente a otra al 100%.
Lo que nos queda claro es que sin los Crawlers sería muy complicado tener todo el contenido existente en internet.
Cómo puede rastrearnos Google
Existen distintas formas por las que Google Bot puede acceder a nuestro contenido, entre las más destacadas encontramos:Sitemaps
Enlaces internos
Backlinks
IP
DNS
Aunque si quieres asegurarte de que tu site sea rastreado al 100% es mejor que utilices desde mi experiencia el sitemap, aunque no es necesario al 100% si tu site es pequeño (menos de 1000 URLs).
El uso de una buena arquitectura web, como es por ejemplo la arquitectura silo puede ser de gran ayuda en este proceso.
Cómo saber el Crawling de una web
Si nuestra intención es conocer el Crawling de una web, tenemos dos opciones:Search Console
Logs
Search Console para conocer el Crawling de nuestra web
La opción más simple si queremos ver cuantas veces rastrea Google nuestra web es a través de su propia herramienta para webmaster (Search Console). Entre su muchas funcionalidades que sirven de gran ayuda encontramos la opción de rastreo en Google Search Console > Ajustes > Estadísticas de rastreo.Nada más abrir la pantalla podemos ver los rastreos totales diarios, este dato quiere decir el número de veces que Google Bot ha rastreado nuestra web en un día.
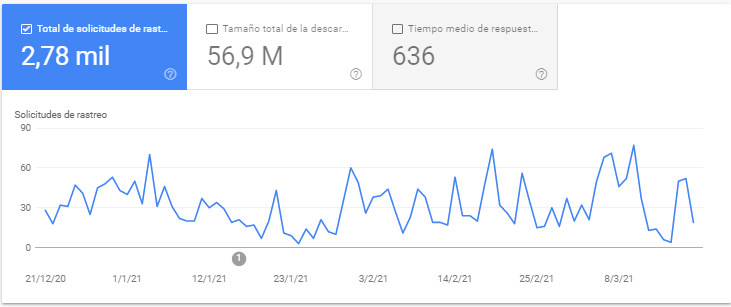
También tenemos el tamaño total de la descarga, para conocer el peso total descargado en Byte.

Tiempo medio de respuesta, para conocer el tiempo que se tardó en obtener el contenido de una página.

Pero esta información por si sola no aporta gran valor, ya que es demasiado poco específica, que un día haya un número mayor o menor de URLs rastreadas no significa por si solo nada, quizás se haya rastreado varias veces la misma URL y nosotros pensemos que se ha rastreado todo el site.
Igual sucede con el tamaño total de descarga o los tiempos de respuesta del servidor. Si un día se rastrean varias redirecciones 301, posiblemente el tiempo de rastreo se reduzca bastante ese día en comparación a otro que se rastreen URLs que dan 200.
La información válida para mí que podemos sacar de este informe es básicamente si existe algún problema en nuestra web o hemos cometido algún error al modificar el robots.txt, pero poca información más concluyente podemos encontrar, al no tener más detalles.
Crawling con análisis de logs
Posiblemente sea la mejor forma de analizar el Crawling de nuestra web y ver cómo se comporta con ella, pero a la vez es el método más complicado, tendremos que convertirnos en unos analistas de Logs para poder comprenderlo.Este análisis es útil para webs que sean muy grandes o muy importantes, Google bot trata de forma diferente cada web y para poder comprender al bot necesitamos este análisis. Quizás no es necesario para la mayoría de web del mundo, pero si de verdad quieres comprender como Google bot rastrea tu web tendrás que usar esta metodología.
Con ella aprenderás:
Si tu site se rastrea de forma total o parcial en un periodo de tiempo determinado
Qué factores afectan de verdad al Crawling de tu web
Podrás crear un robots.txt personalizado para tu web y no uno predeterminado sacado de un artículo de blog que seguramente te perjudique más que ayude
Saber si Google está rastreado URL que no debería
URLs que dan 200 que no debería existir en tu site
Errores 5xx de tu servidor
Bloqueos de robots.txt que están afectando negativamente a tu SEO
URLs que han dejado de rastrearse
etc
Uno de los momentos en el que aprendí más sobre SEO, en especial sobre Crawling de Google fue con el análisis de Logs. Lo cierto es que no fue un proceso sencillo, pero te aseguro que te sorprenderá toda la información que aprenderás y te darás cuenta de que la mitad de los post que hablan sobre Crawling son réplicas de otros post sin ninguna base.
Conclusión
Ahora que ya sabes un poco más sobre el Crawling, ten en cuenta que es un proceso fundamental si quieres que tu web aparezca en Google.Espero que te haya gustado el post y te atrevas a realizar un análisis de Logs para seguir aprendiendo de tu proyecto y como puede mejorar tu SEO.
Fuentes:
Moz
Fuente: este post proviene de antoniomunoz, donde puedes consultar el contenido original.
¿Vulnera este post tus derechos? Pincha aquí.
Creado:
