
Fuente: BlogTopSEO
Esta mañana fueron publicados los nuevos comandos estándares del archivo robots.txt en un artículo oficial de Google webMasters. También tienen sus fundamentos en uno de los lenguajes padres de la programación: C++. Vamos a ver estas novedades y cómo aplicarlas para exprimirles todo el jugo. ¿Listo?
Biblioteca de comandos Esta biblioteca ha sido modificada ligeramente y publicada en código abierto C++ para ayudar a los desarrolladores a crear herramientas que reflejen mejor el análisis y la coincidencia de robots.txt de Google.
Google ha incluído un pequeño binario en este proyecto que permite probar una URL única y un agente de usuario dentro de un archivo robots.txt. Además, usa como sistema de compilación oficial: Bazel. Este es compatible con la mayoría de las plataformas principales (Linux, Windows y MacOS).
Comandos importantes tener:
. user-agent (nombre del/los buscadores). disallow (deshabilitar seguimiento)
. allow (habilitar seguimiento)
. sitemap (URL del mapa del sitio)
En esta herramienta gratuita de Google puedes probar la funcionalidad de tu archivo robots.txt: Robots Testing Tool obtendrás un resultado así:
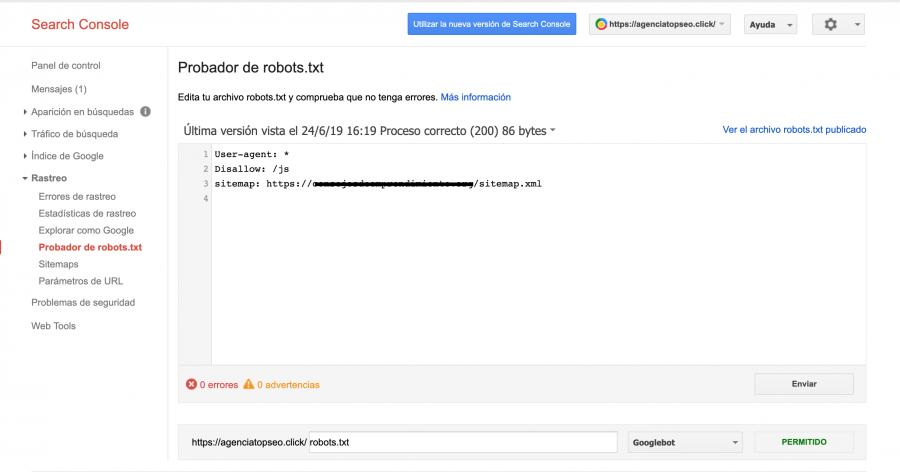
ejemplo prueba robots.txt
Comando abierto del archivo Robots.txt
Como dije antes, existen miles de comandos que se pueden utilizar, pero si no tienes los conocimientos en programación necesarios. Simplemente puedes hacer un archivo abierto para que los buscadores rastreen tu web y no te dejen por fuera. Yo he aplicado:User-agent: *
Disallow: /js
sitemap: URL del mapa de tu sitio
Puedes copiar y pegar estos en tu archivo; estos significan: todos los motores de búsqueda tienen acceso a todos los archivos con excepción al JavaScript y pueden indexar todo el contenido; imágenes, categorías, entradas y páginas.
Si no quieres que se indexe un determinado contenido, como una página o una categoría simplemente puedes añadir una etiqueta noindex. Eso resolverá el problema.
Ubicación y nombre del archivo Este punto permanece intacto, se debe nombrar robots.txt con formato UTF-8 y debe ser escrito separados con líneas (nada nuevo). Lo que sí es nuevo es que en estas novedades se podrá aplicar al protocolo FTP, Google también ha especificado que no serán anunciados errores en el archivo. Esto quiere decir que Googlebot leerá e interpretará sólo las líneas con comandos válidos; ignorando todo lo demás. ¡Hay que estar pendiente en la redacción!
El archivo debe ser subido a la carpeta principal del sitio (public_html). Para los subdominios se debe aplicar el mismo principio; dentro de la carpeta principal del subdominio y colgar el archivo robots.txt ahí dentro.
Ejemplos de URL válida del archivo: https://ejemplo.com/robots.txt
En caso que no se cuente con certificado SSL: http://ejemplo.com/robots.txt
Se han anunciado otras formas URL válidas para subdominios, pero son avanzadas; te recomiendo que lo subas a la carpeta public_html, te ahorrarás muchos dolores de cabeza
Ejemplo de sintaxis avanzada:
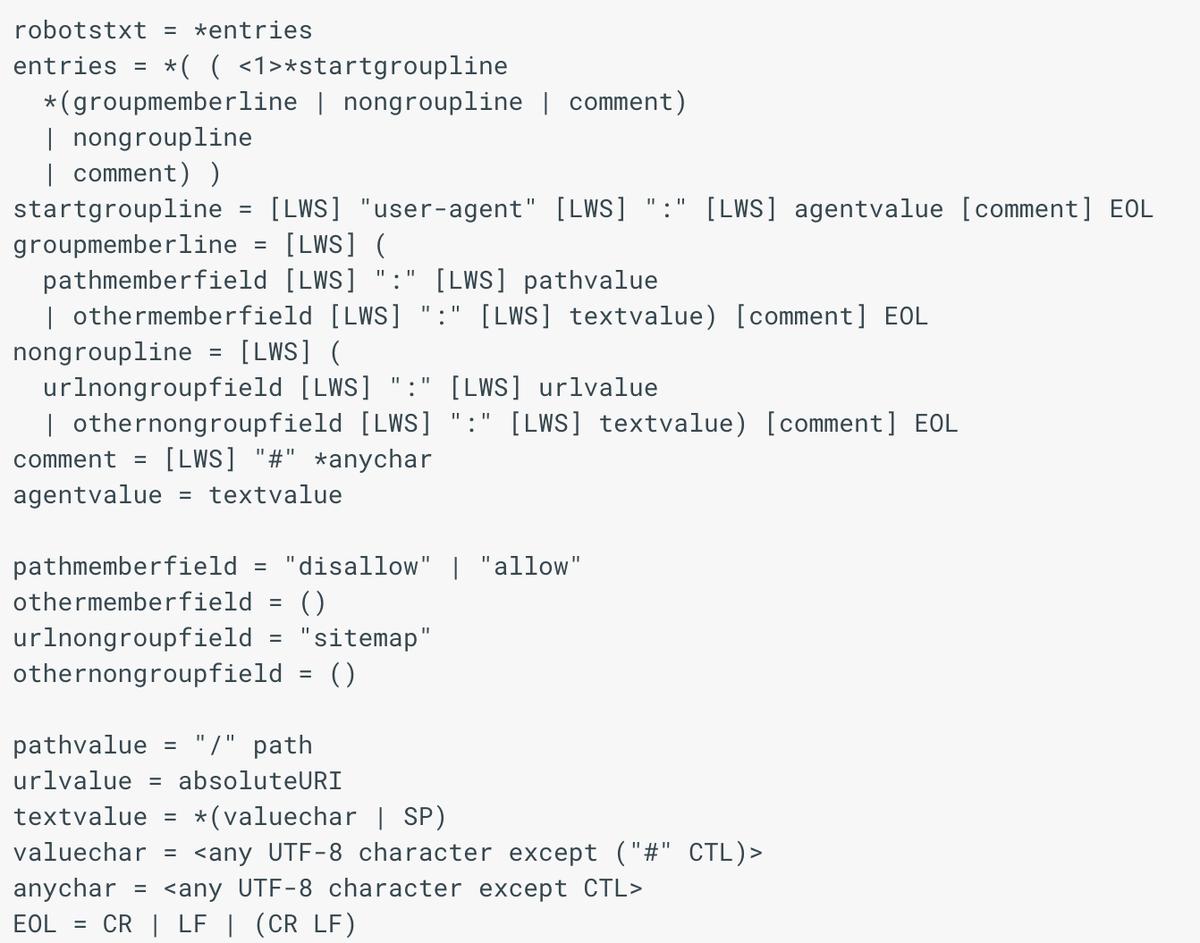
ejemplo de sintaxis avanzada, fuente: Google dev.
Como puedes ver, si no tienes idea de programación se vuelve un jeroglífico, Así que !Mantenlo Simple!
Conclusión Con estos conocimientos puedes tener un archivo robots.txt acorde con las nuevas exigencias; has implementado las buenas prácticas en línea, puedes probar si funciona y todos los buscadores podrán encontrar e indexar tu contenido.
Si te ha gustado este post ¡compartelo! alguien que conoces podría disfrutarlo también.
Fuente: este post proviene de BlogTopSEO donde puedes consultar el contenido original.
Fuente: este post proviene de El Blog de Gian Top SEO, donde puedes consultar el contenido original.
¿Vulnera este post tus derechos? Pincha aquí.
Creado: