En este post vamos a ver en primera instancia que es un logs y para qué sirve, como obtenerlos y que herramientas podemos usar para ejecutarlos, y porque son importantes para nuestra estrategia SEO y la optimización de nuestro Crawl Budget.
Este tipo de análisis es muy recomendado para e-commerce o webs muy grandes, no es menos importante realizarlo en proyectos con un número de URL pequeño, ya que nos van a arrojar información muy interesante.
Contenido
¿Qué son los Logs y de que están compuesto?
¿Cuáles son las partes de un Log?
IP de la visita
Fecha y hora
Código de respuesta
Tamaño de la descarga
URL visitada
User Agent
¿De dónde cogemos el archivo de log?
Filezilla.
Cpanel
Análisis del Crawl Budget y como este influye en nuestro posicionamiento
¿Qué tipo de información podemos obtener de un análisis de logs?
Peticiones por bots o “bots”.
Tendencia de peticiones:
Por tipos de Errores 4xx – 3xx – 5xx
URL duplicadas o inconsistentes.
URL Huérfanas o sin rastrear.
Conclusión acerca del análisis de logs.
¿Qué son los Logs y de que están compuesto?
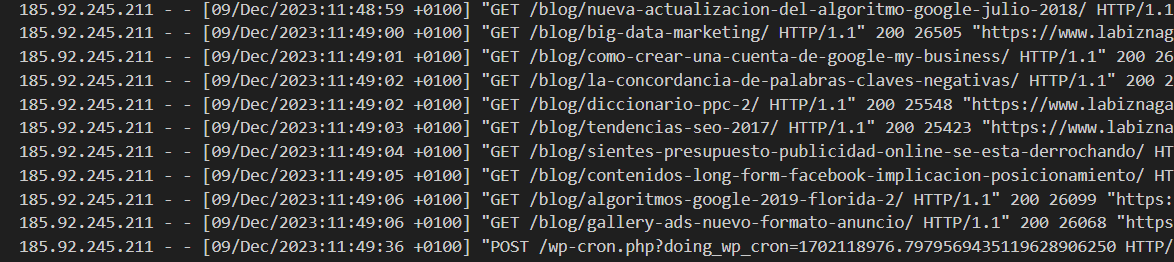
De manera sencilla diremos que un logs es un archivo o fichero, que registra todas las peticiones, o hits, que se realizan en nuestro servidor, ya sean de distintos bots, de un navegador o de alguna herramienta que realice peticiones al servidor donde esté alojada nuestra web.Este archivo, va a recoger información como la URL visitada, día y hora, status code que ha obtenido, tamaño En definitiva, como ahora veremos un log tiene varias partes con distinta información muy útil
¿Cuáles son las partes de un Log?
72.14.201.63 – – [21/Sep/2023:16:43:47 +0200] “GET /blog/como-saber-cuantas-busquedas-tiene-una-palabra-en-google/ HTTP/1.1” 200 31423 “https://www.google.com/” “Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Mobile Safari/537.36″Chrome/113.0.0.0 Mobile Safari/537.36”Vale, si, ves esto y te puedes asustar, pero desgranémoslo:
IP de la visita
14.201.63Fecha y hora
21/Sep/2023:16:43:47 +0200Código de respuesta
200Tamaño de la descarga
31423URL visitada
/blog/como-saber-cuantas-busquedas-tiene-una-palabra-en-google/User Agent
Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36Puede que en función de la configuración del servidor, o del tipo de log que estés analizando haya más información, pero para nuestros análisis SEO, es lo que necesitamos.
Pero claro, visto así, poco análisis podemos hacer y cuando trabajemos con archivos de varios días o semanas, no podemos ir uno a uno. Más adelante veremos distintas herramientas de Análisis de Log más comunes o utilizadas.
¿De dónde cogemos el archivo de log?
Filezilla.
Existen varias alternativas para descargarte este fichero. La más utilizada por nuestra parte es a través de la una Conexión FTP por Filezilla. (Quizás tengas que preguntarte al técnico de IT, por si está escondido en una ruta muy profunda, pero por lo general, nada más conectarte al FTP, veras una carpeta que se llama Log).Cpanel
Si estas usando Cpanel, deberas irte al índice: “Acceso sin procesar”.Como comentábamos anteriormente, depende de la configuración del servidor podrás encontrarte esos archivos de cada día, que cada archivo recopile la información de varios días.
Análisis del Crawl Budget y como este influye en nuestro posicionamiento
Antes de ver que podemos sacar con nuestro análisis de logs, tenemos que entender cuál es el fin de este análisis, que no es otro que el de optimizar nuestro Crawl Budget, que sobre todo en webs con muchas URL, puede ser un auténtico problema.Con esto lo que vamos a intentar es optimizar el presupuesto de rastreo de google en particular, y del resto de bots en general, para que no dediquen tiempo a zonas de la web que bien no son interesantes como modelo de negocio, como puedan ser una política de privacidad, o bien son url que por algún motivo, no deberían de estar siendo rastreadas, pero sin embargo, si lo están siendo.
Un punto importante que no hemos comentado anteriormente, es que con el análisis de logs vamos a poder ver el comportamiento “real” de los bots en nuestra web. Por el contrario, con herramientas como screaming frogg vamos a tener un comportamiento “simulando” ser Google, o el user agent configurado, por lo que hay información que no vamos a poder conocer.
¿Qué tipo de información podemos obtener de un análisis de logs?
Una vez descargado nuestro fichero y procesado con alguna herramienta (nosotros trabajamos con Screaming Frogg log Analyzer, pero existen otras opciones como Seolyzer).Podremos obtener información muy útil para nuestro análisis. ¿Cuáles? Veamos:
Peticiones por bots o “bots”.
Si bien por lo general nuestro principal objetivo es resultar atractivos para google, es posible que otros bots nos estén dando mucho de su tiempo, incluso, personas haciéndose para por algún bots para atacarnos o detectar si alguien con su herramienta de screaming frogg nos ha hecho un crawleo de la web.Tendencia de peticiones:
Si tenemos un archivo de logs de por ejemplo, unas semanas, podremos ver si existe una tendencia a la baja en cuanto al número de peticiones totales en nuestra web, y detectar si se está produciendo algún tipo de problema técnico que esté induciendo a este problema. Y no solo en general, podremos hacer este análisis por url específica o incluso por directorios y ver cuáles de nuestras verticales de productos o servicios está siendo más importante para google.Por tipos de Errores 4xx – 3xx – 5xx
Podremos detectar si estamos teniendo muchas peticiones a URL con errores 404 y tomar medidas de corrección, como redirecciones, o eliminar si se han quedado enlazadas en alguna parte de la web o incluso en algún sitemapsErrores 300, verificar si son URL que aún está asimilando Google esta redirección, o pueden ser enlaces mal puestos que apuntan a URL redireccionadas, o se nos han quedado en sitemaps.
Errores 500, podremos observar si se están produciendo errores de este tipo en momentos puntuales o habituales en nuestra web, y tratar de subsanarlos, ya que errores de este tipo habitualmente nos van a penalizar.
URL duplicadas o inconsistentes.
Podremos detectar si estamos teniendo peticiones a URL que no nos interesan, por tipo de negocio, o por que puedan ser duplicadas como URL con filtros de colores, tamaño, talla etc…com/categoría/titulo
com/categoria/titulo?q=informacion+sobre+contenido+dulpicado
En estos casos, si consideramos que no queremos que google dedique tiempo a este tipo de URL ya que no son interesantes para los bots, podemos bloquearla por robots.txt para evitar que se realicen peticiones a ellos y optimizar el crawl Budget.
Del mismo modo, podremos ver si hay peticiones a url mixtas, con y sin HTTPS (por si en alguna migración de alguna web antigua algo se nos ha escapado)0 y contenido inconsistente. Este tipo van a ser URL que durante un espacio breve de tiempo (duran los días que podamos analizar con los logs) han dado códigos de respuestas distintos durante este tiempo. Por ejemplo, url que habitualmente dan 200, pero por algún motivo (cambios o caídas) pueden dar 301 o 404, incluso hasta errores 500.
En estos casos, habría que analizar cada caso en partículas para detectar el motivo de esta inconsistencia.
URL Huérfanas o sin rastrear.
Otro tipo de información que podemos encontrar en esta tipo de análisis, y que nos va a permitir optimizar el presupuesto de rastreo que tenemos son las url huérfanas o sin rastrear. Este tipo de errores puede venir provocado por una mala arquitectura web.Las URL huérfanas son aquellas que no están vinculadas desde ninguna otra página dentro de nuestro sitio web. Estas URL pueden ser problemáticas porque carecen de enlaces internos que las conecten con otras partes del sitio y puede tener un impacto negativo en términos de posicionamiento y visibilidad y de negocio si son importantes para nosotros.
Este tipo de URL lo encontraremos por lo general cruzando datos de nuestros análisis de logs y peticiones por URL con un crawleo que hagamos de nuestra web y detectemos URL que aparezcan en los logs, pero no en dicho crawleo.
En estos casos, deberemos pensar si son URL importantes y enlazarlas desde la web, o si por el contrario no nos interesan y son URL que podemos “eliminar” con una redirección o un 410 para eliminarlas de google.
¿Y si el caso es inverso? ¿Url que aparecen en un crawleo, pero no en nuestro informe de logs? En estos casos al igual que en el caso anterior, depende. ¿Son importantes para nuestro negocio? Debemos valorar si queremos priorizarla por encima de otras URL, ya sea enlazándola desde zonas de la web con más peticiones y mayor rastreo o incluyéndolas en sitemaps si no lo estuvieran.
Aquí podremos recurrir a ver informes de Google Search Console de URL sin descubrir o url descubiertas sin rastrear, para ver si guarda correlación con que no tenga peticiones de google en las últimas semanas o meses.
Conclusión acerca del análisis de logs.
Este tipo de análisis quizás está asociados a webs más grandes, con miles o millones de url, pero es interesante realizarlo en webs más pequeñas ya que muchas veces, con pequeños cambios de optimización de nuestros archivos robots.txt o incluso creando o cambiando sitemaps, podremos obtener mejores resultados en cuando a la optimización de nuestro crawl Budget y por ende a nuestro posicionamiento.También ten en cuenta que para obtener mejores resultados en este análisis, siempre vas a necesitar de cruzas datos con otras herramientas como Google Analytics 4 o Google Search Console.
Esperemos que te haya resultado de interés esta guía SEO sobre Análisis de Logs paso a paso, recuerda que puedes contactar con nosotros, ya que como agencia de posicionamiento SEO, estaremos encantados de ayudarte. También puedes optar por seguir consultando nuestro blog, puede que te interese: Deep links o enlaces profundos.
Valora este artículo sobre [Guía SEO] Dominando el Análisis de Logs paso a paso
5/5 - (3 votos)
Fuente: este post proviene de LA BIZNAGA DIGITAL , donde puedes consultar el contenido original.
¿Vulnera este post tus derechos? Pincha aquí.
Creado: